
Images enter Google’s index through automated crawling, structured metadata, and SERP‑level aggregation, which means that once a photo is publicly hosted it can become a persistent part of the web’s visual footprint. Reputation management is the systematic control of how entities appear in search‑driven information systems; online reputation refers to how search visibility, visual content, and text‑signals collectively shape user perception of credibility and risk.
How does Google index images and what is the process?
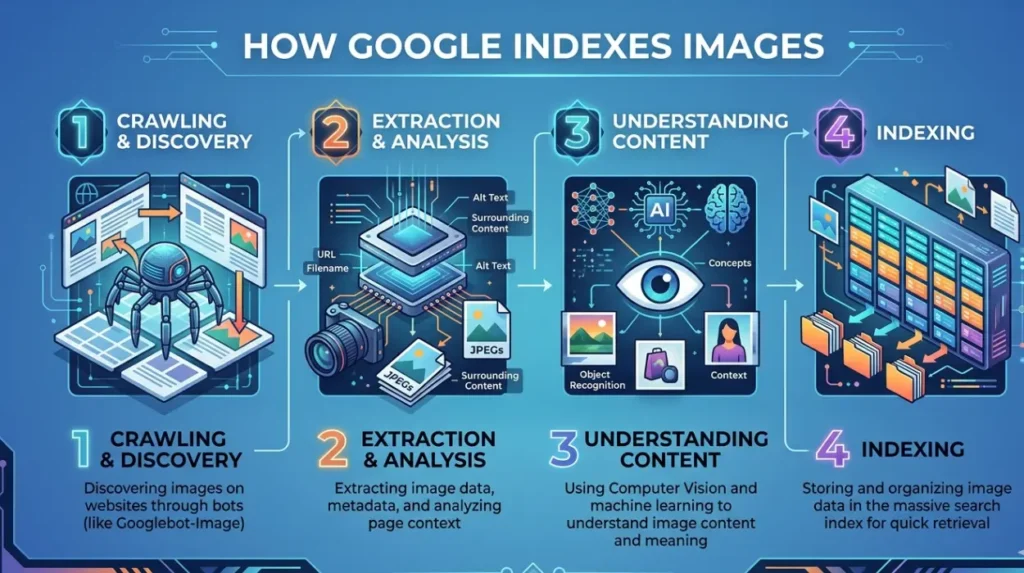
Google indexes images by crawling public web pages, extracting visual files, and associating them with surrounding text, metadata, and user‑behaviour signals. The system treats images as structured data that can be ranked and surfaced in Image Search and regular SERPs alongside standard web content. The indexing mechanism is automatic, not opt‑in, so nearly any public image on a crawlable site can enter the ecosystem.
Dive Deeper With Our Expert Guides and Related Blog Posts:
Why Indeed Reviews Are Hard to Remove and What the Platform Policy Actually Covers
Why Harmful Websites Stay in Google Search Even After You Report Them
Within the search ecosystem, “image indexing” refers to the process of discovering, analysing, and storing photo‑files so that Google can match them to relevant queries. Crawlers follow links, download images, and record related information such as ALT text, nearby page text, EXIF metadata, and file‑type properties. The system then groups these elements into a visual‑index layer that underpins Google Images and image‑rich results.
The impact on search visibility is substantial. Once indexed, an image can appear in image‑results, article‑snippets, news‑tiles, and even third‑party galleries, multiplying its potential exposure. The SERP‑evaluation of a page often includes its visual‑signals, so images shape not only how users perceive the entity but also how the system ranks the underlying web property. A single indexed image can therefore anchor a broader perception of the entity’s credibility or risk.
What metadata and context signals shape image‑indexing and ranking?
Metadata and contextual text around an image—such as ALT attributes, captions, surrounding articles, and page‑authority signals—shape how Google indexes, ranks, and displays that image. The system does not rely only on visual recognition. It combines image‑features with textual and structural‑signals to infer relevance and trust. The result is that the same photo can surface differently depending on the hosting‑page and its surrounding information.
In ecosystem terms, ALT text defines the image’s semantic label, which tells the system what the image represents in text form. Captions, headings, and adjacent paragraph‑text supply additional context that can override or refine the visual signal. The page’s domain‑authority, backlink‑profile, and historical‑trust signals also influence whether the image is likely to rank strongly or demoted. A high‑authority news‑site, for example, often sees its images rank higher than the same image on a low‑trust forum.
The mechanism operates through a multi‑signal evaluation layer. After crawling, the system builds a combined‑score for the image based on:
- Visual‑feature analysis (objects, faces, composition).
- Proximity to relevant keywords in the page text.
- Quality of metadata such as ALT text and image‑name.
- Host‑site‑reputation and user‑engagement patterns.
The impact on entity perception is indirect but measurable. A photo embedded in an authoritative, fact‑based article tends to reinforce a stable, credible‑image of the entity. The same image in a gossip or low‑quality‑site can amplify negative or speculative narratives, because the SERP‑mix shifts the weight of the surrounding context. Image‑indexing therefore never operates in isolation; it is always part of the broader content‑signal‑landscape.
How do search engines interpret trust and credibility for visual content?
Search engines interpret trust and credibility for visual content by combining host‑site‑authority, user‑engagement patterns, and policy‑signals such as content‑label‑flags or manual‑reviews. The system does not “believe” an image. It treats it as a rendering‑element whose reliability is inferred from the surrounding ecosystem. The SERP‑evaluation of an image is therefore tied to the perceived‑quality of the host page and platform.
Within the ecosystem, an image’s trust‑signal is defined by the reputation of the hosting environment. A photo on a mainstream, regulated news‑site with strong editorial‑controls receives a higher‑implied‑credibility weight than the same image on an anonymous image‑board or low‑authority blog. The system also analyses click‑patterns, dwell‑time, and user‑feedback signals associated with the image‑result, which can subtly adjust its ranking and prominence.
The mechanism works in layers. First, the system associates the image with the host‑site and its trust‑signals. Second, it checks for explicit‑policy‑flags, such as labels for sensitive‑content, graphic material, or policy‑violation‑tags. Third, it observes user‑interaction data, including whether users repeatedly click, ignore, or flag that image‑result. The combined output shapes where the image appears in image‑search and how likely it is to surface in standard SERPs.
The impact on perception is multifaceted. A credible‑image on a trusted‑site reinforces the entity’s reputation by visually anchoring its narrative. A misleading‑image with a manipulative caption on a low‑trust‑site can distort perception, even if the image‑itself is technically authentic. The system’s inability to fully “understand” intent means that the surrounding context often does the interpretive work for it.
What privacy rights apply to your photos in the UK when they appear in Google Images?
UK privacy rights such as the GDPR‑inspired UK data‑protection regime and common‑law privacy‑and‑image‑consent‑principles shape what can be done when personal photos appear in Google Images. These frameworks govern the lawful use, storage, and dissemination of images that depict identifiable individuals, but they do not grant automatic removal from all search‑level exposure. The system distinguishes between hosting‑site‑obligations and search‑engine‑indexing‑rights.
Within the UK‑legal framework, “privacy rights” refer to the conditions under which a person can object to or demand removal of images that contain their personal data or likeness. The GDPR‑style regime applies to images that are personal data, such as photos that identify a living individual and are used in a way that affects their rights. A data‑subject may request that the host site remove or anonymise the image, but the removal‑from‑Google is a separate, secondary‑step that depends on the host action and follow‑up‑delisting‑requests.
The mechanism operates on two levels. First, the data‑subject or legal representative files a complaint or takedown‑request with the website hosting the image, citing unlawful processing, lack of consent, or inappropriate use. If the host removes the image, Google can then be asked to de‑index the former URL, which may reduce its presence in search. If the host does not comply, the data‑subject may need to escalate the matter through enforcement‑bodies or courts, which can issue orders that then feed into Google’s legal‑removal‑process.
The impact on search visibility and perception is partial. Successful removal at the host level can shrink the pool of indexed‑image‑URLs, which lowers the chances of the photo appearing in Google Images or SERP‑results. However, the system can still index copies or mirrors, caches, or third‑party shares, which means complete erasure is not automatic. The process focuses on reducing exposure and aligning the SERP‑surface with the individual’s legal‑rights, not on creating a guaranteed‑total‑removal.
How do image‑takedown and delisting mechanisms work in practice?
Image‑takedown and delisting mechanisms operate by first securing removal from the host site and then requesting that Google de‑index or restrict the visibility of the former image‑URLs. The process is not a single‑button‑removal. It is a multi‑stage workflow that depends on copyright‑ownership, data‑protection‑grounds, or explicit‑policy‑violations. The system evaluates each case against its internal‑rules and relevant‑jurisdiction‑law.
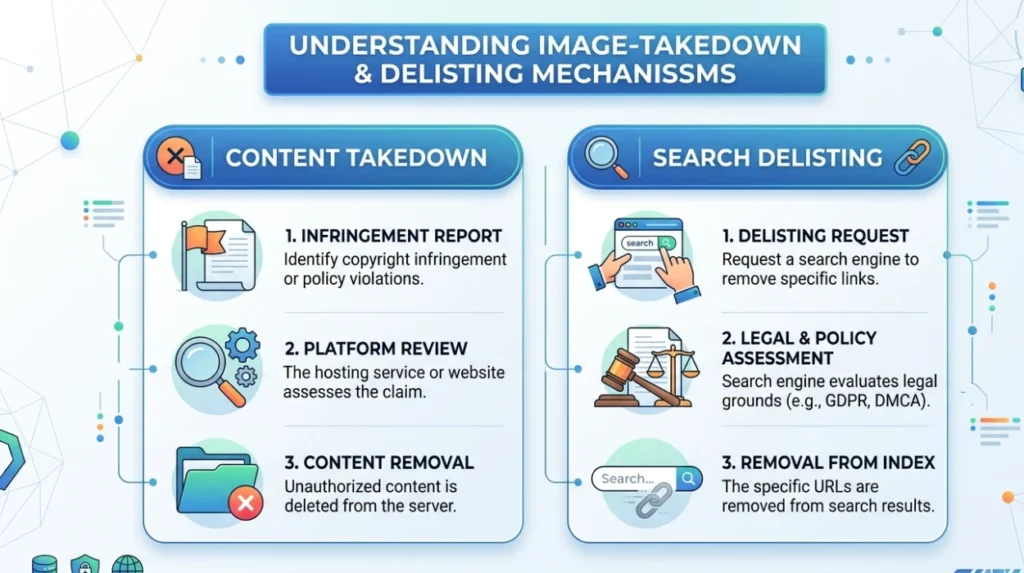
Within the ecosystem, “takedown” refers to the forced removal of the image from the hosting environment, often via legal or platform‑policy action. “Delisting” refers to the search‑engine‑level step where the indexed reference to that image URL is suppressed or removed from the SERP. The order typically matters: if the host keeps the image live, Google’s delisting options are limited unless the image clearly breaches explicit‑policy or court‑orders.
The mechanism usually follows a sequence.
- Identify the original hosting URL of the image and any mirrors or republication‑points.
- Send a formal takedown notice to the host based on copyright, privacy, or content‑policy‑grounds.
- If the host complies, submit a delisting‑request to Google specifying the de‑activated or removed URLs.
- In some cases, file additional legal‑complaints or enforcement‑requests where the host refuses to remove the image.
The most effective routes impact on search visibility is measurable but not absolute. Successful delisting eliminates the indexed‑entry for that specific URL, which can reduce the frequency with which the image appears in Google Images and related‑web‑results. However, if the image is republished on other sites or archived in third‑party systems, new indexed‑instances can arise. The result is that takedown and delisting alter the visual‑SERP‑distribution without guaranteeing a permanent‑erasure.
How do images influence reputation signals and SERP perception?
Images influence reputation signals by anchoring emotional and contextual cues that users interpret alongside textual results, which shapes how they judge an entity’s credibility and risk. Within the SERP, visual elements act as immediate perceptual shortcuts, so the choice of images that appear for a search term can tilt the perceived‑trust‑band for the entity. The system’s reliance on image‑rich features in some verticals amplifies this effect.
In ecosystem terms, an image‑rich result defines part of the entity’s digital footprint, especially for people, brands, or organisations where visual identity matters. A consistent set of professional, controlled‑images can signal stability and credibility. In contrast, invasive, sensational, or misleading photos can create a heightened‑risk perception, even if the surrounding text is neutral. The SERP‑composition of images thus becomes part of the broader reputation‑signal‑stack.
The mechanism operates through user‑attention and cognitive‑load. Images are processed faster than text, so they often frame the user’s first‑impression of the entity before the written detail is read. The SERP may feature multiple images for a single search term, and each one carries a small but cumulative effect on perception. A negative‑image cluster, such as mugshots, candid‑shots from contentious events, or low‑quality‑captures, can therefore distort the entity’s reputation even if the factual‑narrative is incomplete or outdated.
The impact on entity perception is durable because images are harder to forget than text. Once a specific image becomes associated with the search term, it can anchor the narrative for future‑searches, even if the text‑results change. The system’s continued indexing of that image, or its re‑appearance through mirrors and archives, extends the reach of the visual‑signal throughout the SERP‑landscape. This is why the question of what the most effective routes are for getting a Google Image removed in the UK carries significant reputational weight.




