
Reputation management is the practice of analysing, influencing and controlling how an entity is perceived across digital information systems.
Online reputation refers to the cumulative set of signals, indexed content and entity associations visible through search ecosystems.
Why does online content persist in search ecosystems?
Content persists because content indexing, archival redundancy and entity-linked authority establish durable reputation signals that resist unilateral removal.
Definition: Persistence is the property by which published items remain discoverable within search ecosystems despite deletion attempts. Persistence refers to cached copies, third-party reposts and metadata traces within indexing systems.
Mechanism: Search engines crawl and index web resources, then store representations in multiple layers (live index, cache, and third-party archives). When content is removed at source, crawlers detect a change and mark the URL for re-crawl; however, cached snapshots and downstream copies remain. Aggregators and mirrors re-publish content, and archival services intentionally preserve historical records. Robots.txt, noindex tags and takedown notices update index signals, but they do not erase cached or archived replicas on other hosts. Links from authoritative domains maintain PageRank-like signals that keep content visible in SERPs even if the original page disappears.
Impact on search visibility or perception: Persistence sustains reputation signals tied to an entity, prolonging negative or neutral visibility. Archived or cached versions appear in SERP evaluation and inform entity perception through snippets, knowledge panels and related-search associations. Persistent content continues to contribute to authority metrics and sentiment interpretation long after source removal, complicating corrective actions.
How do search engines interpret trust and credibility for persistent content?
Search engines evaluate trust using a blend of link authority, content provenance, engagement metrics and structured entity data that collectively define credibility signals.
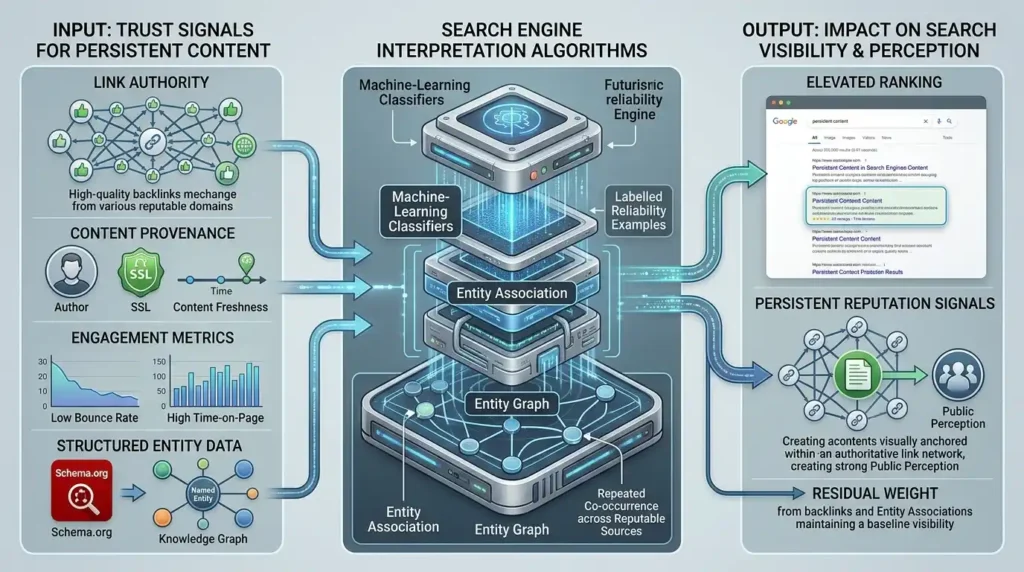
Definition: Trust signals are measurable attributes search systems use to assess content reliability. Trust refers to domain authority, backlink profile, schema, authoritativeness and behavioural engagement within search ecosystems.
Mechanism: Algorithms parse signals such as inbound link quality, host reputation, SSL presence, content freshness and structured data to weight content credibility. Entity graphs associate webpages with named entities, and repeated co-occurrence across reputable sources amplifies perceived legitimacy. Machine-learning classifiers incorporate labelled examples of reliable content to adjust weighting. Signals like bounce rate and time-on-page act as proxy metrics for user validation. When content persists in high-authority contexts or is linked extensively, algorithms treat it as credible, increasing search visibility.
Impact on search visibility or perception: Credibility-driven ranking elevates persistent content into prominent SERP positions, influencing entity perception. Content retained within authoritative link networks generates persistent reputation signals that anchor public perception. Even low-engagement content retains residual weight via backlinks and entity associations, maintaining a baseline of visibility that affects SERP evaluation.
What role does indexing and caching play in content removal outcomes?
Indexing and caching create independent copies and metadata that preserve content state, so removal at source does not automatically remove indexed or cached instances.
Definition: Indexing is the process by which search ecosystems analyse, store and reference web content. Caching is the storage of content snapshots used for faster retrieval and historical reference within search ecosystems.
Mechanism: Crawlers fetch resources and create index entries with metadata (title, snippet, canonical link, crawl timestamp). Search caches store rendered snapshots and may be served when the live resource is slow or removed. Reverse proxies, CDNs and archiving services also store replicated copies. When a source returns a 404 or is taken down, the index marks it stale but retains the cached snapshot until re-crawl or explicit removal via publisher-controlled mechanisms or formal legal requests. Additionally, canonicalisation and URL parameters can lead to duplicate index entries that require coordinated removal.
Impact on search visibility or perception: Cached and indexed remnants remain visible in SERPs as snippets or “cached” links, sustaining reputational references. This persistence allows search users and third-party evaluators to access prior content states, which sustains entity perception over time and complicates reputation signal correction.
Which technical signals anchor content to an entity’s digital footprint?
Anchor signals include persistent backlinks, structured entity identifiers, canonical links and cross-site mentions that bind content to an entity within the entity graph.
Definition: Anchor signals are the metadata and relational attributes that link content to an entity within search ecosystems. Anchors refer to explicit links, schema.org entity IDs, social mentions and media attributions.
Mechanism: Backlinks from authoritative domains transfer link equity and create reference paths in the link graph. Schema and structured data embed explicit relationships (author, organisation, sameAs) into webpages, enabling entity resolution. Social platform mentions attach native identifiers and usernames to content, while image metadata and file names contribute additional entity association. Aggregated mentions across independent hosts form co-reference clusters that search systems map to a single entity node.
Impact on search visibility or perception: Strong anchor signals increase the probability that persistent content will appear in association with the entity in SERP evaluation, knowledge panels and related-results features. Removing the source does not remove anchor signals embedded across third-party hosts, so the entity’s reputation remains influenced by those anchored references.
How does sentiment and review data affect long-term perception in SERPs?
Sentiment and review data form structured reputation signals that feed ranking models and influence entity perception via review snippets, star ratings and sentiment aggregates.
Definition: Sentiment data is the aggregated polarity of textual content; review signals are explicitly structured feedback elements that search ecosystems parse and display. Both refer to quantifiable evaluative inputs within search ecosystems.
Mechanism: Natural language processing extracts sentiment from textual items and assigns polarity scores. Review schema (ratingValue, reviewBody) enables crawlers to identify and display structured opinions. Aggregated sentiment influences entity perception models, which factor into ranking adjustments and snippet generation. Platforms that centralise reviews become authoritative sources; negative reviews hosted on these platforms persist as durable reputation signals due to platform-level indexing and cross-linking.
Impact on search visibility or perception: Persisting negative sentiment or low ratings drive SERP features that foreground evaluative content, such as review snippets and “about” sections. Such features bias entity perception and influence click-through rates and engagement metrics, reinforcing the content’s ranking through feedback loops in the ranking model.
Why do third-party copies and archives resist standard takedown actions?
Third-party copies and archives operate independently, preserving content under different legal and technical regimes, which prevents unilateral removal from search ecosystems.
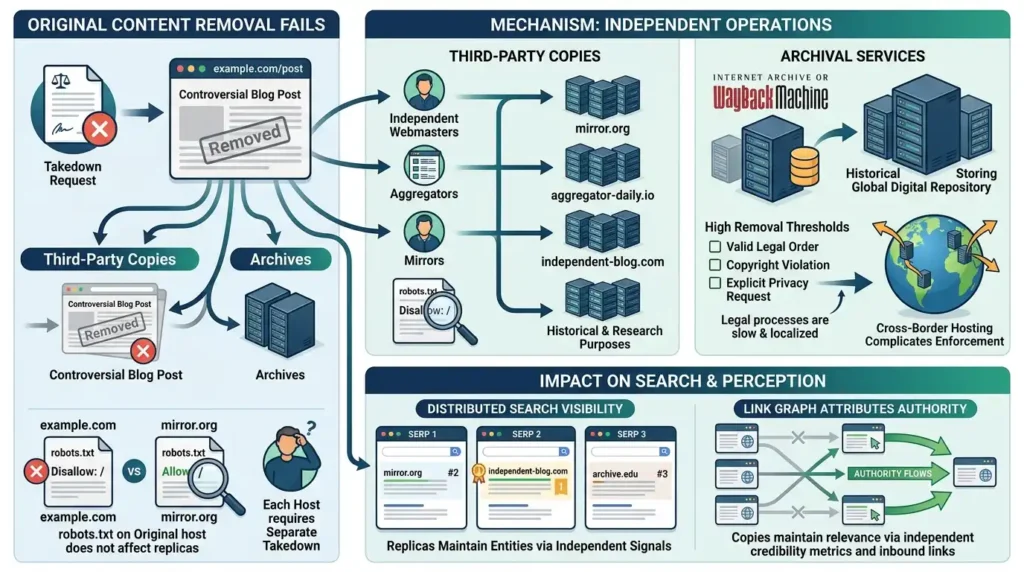
Definition: Third-party copies are reproductions hosted by independent webmasters, aggregators or archiving services. Archives refer to intentional repositories preserving web history.
Mechanism: Once content is crawled and copied, downstream hosts create new origin points with separate domain authority and hosting controls. Each host requires its own removal process robots.txt on the original host does not affect replicas. Archival services preserve content for historical and research purposes and implement legal thresholds for removal. Search engines rely on source-origin signals but also index replicas; the link graph may attribute authority to the replica if it accumulates inbound links or engagement. Legal takedowns apply jurisdictional rules; cross-border hosting and mirrored networks complicate enforcement.
Impact on search visibility or perception: Third-party persistence spreads reputation signals across distinct domains, diluting the effect of removing a single source. Search visibility becomes distributed; replicas may occupy SERP positions and maintain entity perception through independent credibility metrics.
Which routes actually work to remove content from the internet in the UK?
Effective removal requires legal takedowns, host or platform compliance, and coordinated de-indexing requests, each applied to specific hosts or archives rather than to the index as a whole.
Definition: Removal routes are the procedural mechanisms available to remove content from hosts, indexes or archives within UK jurisdiction and internationally.
Mechanism: Legal remedies include court orders and statutory instruments that compel hosts or search engines to remove content. Platform compliance processes enforce terms of service to remove content when it violates platform rules. De-indexing requests to search engines remove URLs from search visibility but do not erase underlying copies. Coordinated action combines legal notices to hosts, takedown forms to platforms, and formal de-indexing petitions to search engines to address all instances.
Impact on search visibility or perception: Removing index entries reduces SERP visibility and can reduce snippet exposure, thereby altering entity perception. However, unless replicas and archives are addressed, de-indexing only partially mitigates reputation signals. Persistent reputation signals remain in third-party copies and structured data unless those nodes are separately remediated.
How do entity graphs and knowledge panels perpetuate historical content?
Entity graphs synthesise cross-source signals and knowledge panels extract authoritative summaries, so historical content persists through entity-linked attributes even after source deletion.
Definition: An entity graph is a structured representation of entities and their relationships within search ecosystems. Knowledge panels are curated summaries that present high-level entity data derived from the graph.
Mechanism: Search ecosystems ingest structured data, public records and high-authority sources to build entity nodes. Historical content contributes attribute values (dates, roles, associations) that persist in the graph. Knowledge panels display consolidated facts and linked sources; if historical material is cited by authoritative references used to populate the graph, panel content retains those associations. Even when original pages vanish, the graph retains extracted facts and references until upstream data sources issue corrections.
Dive Deeper With Our Expert Guides:
How Online Content Removal Works and Why It Takes Professional Expertise
What a Content Removal Service Does and Who Actually Needs One
Impact on search visibility or perception: Persisting entity attributes in graphs anchor reputation signals and surface in SERPs via knowledge panels and related searches. This perpetuation sustains entity perception and influences subsequent SERP evaluation and click behaviour, independent of live page presence.
Content persists in search ecosystems because indexing layers, archival redundancy, anchor signals and entity-linked authority create durable reputation signals that resist unilateral removal. Search engines evaluate trust through link authority, structured data and engagement metrics; these evaluative mechanisms amplify persistent items into visible SERP features. Effective mitigation requires addressing each node that contributes to the reputation signal: host copies, archives, structured data and search index entries, because de-indexing a single URL does not erase the distributed network of references. Understanding these technical and procedural mechanisms clarifies why online material rarely disappears without coordinated intervention and why reputation management depends on system-level remediation.
For more detail explore:
Which Routes Actually Work to Remove Content From the Internet in the UK
How long does Facebook content removal take?
Removal time varies by complexity; simple takedown requests on Facebook can be processed within hours to a few days, while legal notices or cross-platform removals take weeks. Track status via Facebook’s support interface and keep records of submission dates and reference numbers for follow-up.
What grounds justify requesting Facebook content removal?
Valid grounds include copyright infringement, defamation, privacy breaches, and content violating Facebook’s Community Standards or UK law. Provide precise evidence (timestamps, URLs, legal documents) to support removal requests and reference the specific policy or legal provision.
Can deleted Facebook posts still appear in Google search results?
Yes; deleted Facebook posts can persist in Google’s index, caches, or third-party archives even after removal. Submit de-indexing requests to search engines and address any archived or mirrored copies on other hosts for comprehensive removal.
How do I prove ownership or harm when requesting Facebook content removal?
Prove ownership or harm with original files, metadata, screenshots, registration records, or statutory declarations detailing the infringement or damage. Attach clear documentation to takedown forms and reference applicable UK legal standards to strengthen enforcement.




