
A harmful website can continue ranking in Google after complaints are made because search engines treat complaints as input signals, not as automatic removal triggers, and because ranking depends on indexing, authority, and SERP‑evaluation rules rather than on user‑dislike alone. Complaints can influence how search engines audit and assess a site, but they do not override the core‑ranking logic that governs which pages appear and how they are ordered.
Reputation management is the study of how digital‑signals combine to shape how brands, entities, and individuals are perceived in search‑driven environments. Online reputation refers to the way that information‑clusters about an entity behave in search ecosystems, including how content is indexed, ranked, and interpreted as trust‑or‑risk‑signals.
What does “reputation” mean within search ecosystems?
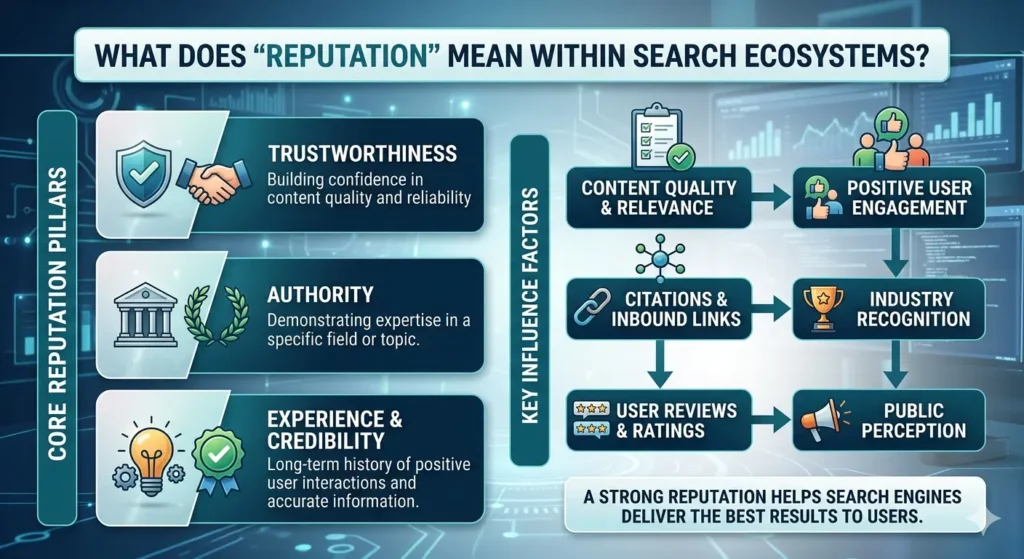
Reputation within search ecosystems refers to the pattern of signals that search engines associate with an entity when they rank pages, present snippets, and choose which content appears in top‑position results. It is not a single rating, but a distributed‑set of signals that emerge from how content is linked, cited, and interacted with across the web.
Search‑reputation is defined as the collective‑behaviour of indexed‑content that mentions, reviews, or discusses an entity, and how those items are weighted in ranking models. This includes pages such as official‑sites, news‑articles, reviews, forums, and social‑mentions that collectively form an entity’s digital‑footprint.
The mechanism operates through:
- Entity‑linking: search engines connect different‑pages to the same entity and track how those pages are referenced.
- Signal‑clustering: sentiment, authority, and freshness are aggregated into overall‑perception‑indicators.
- SERP‑polarisation: users see only the most‑visible subset of reputation‑signals, which can amplify or suppress certain aspects of the narrative.
These patterns show that reputation is not something that exists off‑site; it is produced and interpreted within the search ecosystem itself.
How do search engines interpret trust and credibility signals?
Search engines interpret trust and credibility signals by combining technical‑signals, content‑quality‑indicators, and behavioural‑patterns into internal‑models that estimate how likely a page is to be useful and reliable. Trust and credibility are not binary states; they are probabilistic‑assessments that are continuously updated as new data arrives.
Trust‑signals are defined as the indicators that search engines associate with low‑risk, high‑quality content, such as authoritative‑backlinks, clear‑authorship, and consistent‑domain‑behaviour. These signals work in concert with credibility‑signals, which include factual‑consistency, citation‑patterns, and the presence of authoritative‑sources.
Search engines evaluate these signals through:
- Technical‑health checks: indexing‑status, security‑practices, and page‑speed‑requirements that affect how content is treated.
- Content‑quality‑models: assessing clarity, originality, and alignment with user‑intent through structured‑and‑semantic‑indicators.
- Authority‑network‑analysis: measuring how pages are referenced by other‑trusted‑domains and how those networks cluster around entities.
These mechanisms ensure that trust and credibility are not simply the result of popularity, but of a structured‑evaluation of how information is produced and linked.
How does content ranking influence online reputation and perception?
Content ranking influences online reputation and perception by determining which pieces of information are most‑visible when users search for an entity, topic, or brand. The top‑positions on SERPs act as a de facto‑editorial‑filter, shaping how quickly and easily users encounter specific narratives.
Ranking‑influence is defined as the way that the position, prominence, and diversity of content in SERPs affect how users interpret risk, reliability, and credibility. When negative‑stories or harmful‑pages dominate the top‑ ranks, the perceived‑reputation of the associated‑entity is skewed even if many positive‑pages exist elsewhere.
Mechanisms at work include:
- Attention‑hierarchy: users disproportionately attend to the first‑few results, so high‑ranking‑negative‑items have outsized‑perception‑impact.
- Narrative‑locking: once a certain narrative is reinforced across multiple‑top‑results, it becomes more difficult for alternative‑perspectives to gain traction.
- Sentiment‑bias‑amplification: clusters of negative‑reviews or critical‑articles in top‑positions can create the impression of widespread‑disapproval, even if the sentiment‑distribution is mixed overall.
This dynamic shows that ranking is not just a technical‑feature; it is a structural‑input into how reputation is formed and understood.
Why can a harmful or defamatory website continue to rank after complaints are filed?
A harmful or defamatory website can continue to rank after complaints are filed because search engines treat complaints as evidence within an evaluation‑process, not as self‑executing removal orders, and because ranking is governed by indexing, authority, and SERP‑evaluation‑logic. Complaints may trigger internal‑audits or des‑ranking‑processes, but those changes are not guaranteed and depend on how the content aligns with platform‑rules and legal‑standards.
Harmful‑content‑persistence is defined as the phenomenon where pages that users or entities perceive as damaging remain indexed and visible in search results, even after formal‑or‑informal‑complaints. Persistence can occur when the content meets technical‑and‑quality‑criteria, when it is backed by authority‑signals, or when it cannot be proven to violate specific‑policies.
Search engines evaluate complaints through:
- Policy‑compliance checks: assessing whether the content breaches explicit‑guidelines on defamation, hate‑speech, fraud, or illegal‑material.
- Evidence‑verification: reviewing documentation, legal‑orders, or other‑proof before taking action that alters indexing or ranking.
- Appeal‑and‑revision‑workflows: allowing publishers to contest removal‑or‑suppress‑decisions, which can prolong the period during which harmful‑content remains visible.
These processes mean that complaints initiate a review‑cycle, not a guaranteed‑outcome, and that ranking behaviour is shaped more by systemic‑rules than by individual‑disputes.
How do search engine results pages (SERPs) construct reputation for brands and entities?
Search engine results pages (SERPs) construct reputation for brands and entities by aggregating and ordering content that mentions, reviews, or discusses them, and by presenting that information to users in a structured, narrative‑shaping format. SERPs do not invent reputation, but they curate and highlight the most‑visible subset of signals that define how an entity is perceived.
SERP‑construction is defined as the way that search engines combine titles, snippets, images, and other‑elements into a cohesive‑view of an entity that users interpret as a summary of its credibility. Over time, repeated‑exposure to the same‑pattern of SERP‑composition can reinforce users’ belief that an entity is trustworthy, risky, or controversial.
Key‑constructive‑mechanisms include:
- Entity‑card‑aggregation: extracting information from multiple‑sources to build a compact‑summary that shapes first‑impressions.
- Snippet‑framing: selecting short‑snippets that highlight certain aspects of the narrative, such as negative‑reviews or regulatory‑issues.
- Multimodal‑presentation: mixing images, videos, and reviews into the SERP layout, which amplifies emotional‑and‑visual‑signals alongside textual‑content.
These mechanisms show that SERPs are not neutral‑lists; they are active‑reputation‑constructors that influence how users understand and assess brands.
What role do review signals and sentiment interpretation play in online reputation?
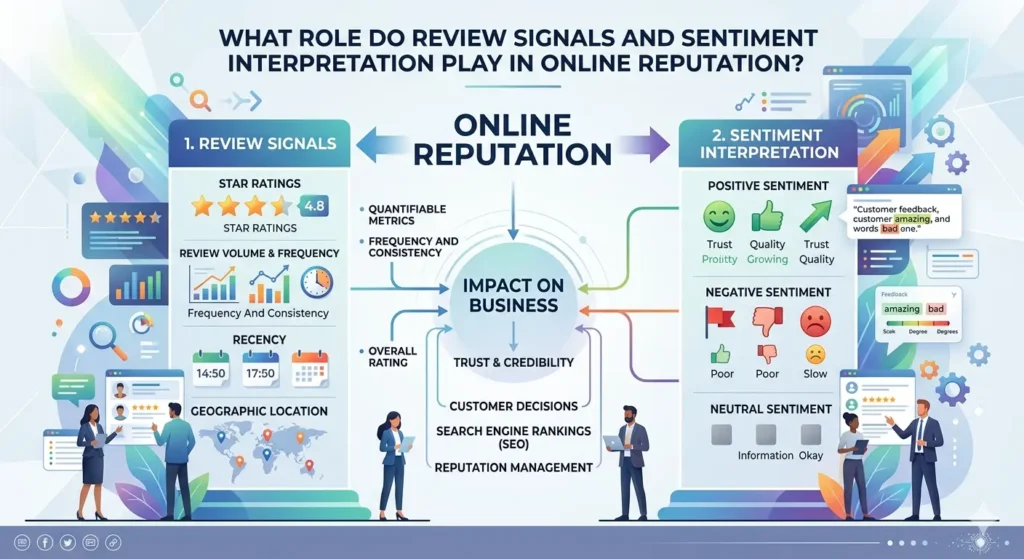
Review signals and sentiment interpretation play a central role in online reputation by providing search engines and users with structured‑data about how entities are evaluated by their audiences. Reviews act as explicit‑trust‑or‑distrust‑indicators, and sentiment‑interpretation allows platforms to infer the emotional‑and‑evaluative‑valence of unstructured‑text for What Legal and Technical Routes Support Removing a Website From Google UK.
Review‑signals are defined as the collection of user‑ratings, star‑scores, and written‑feedback that appear across platforms and are indexed into SERPs or aggregated‑into‑entity‑cards. These signals are used to estimate the perceived‑quality and reliability of a brand, product, or service.
Sentiment‑interpretation refers to the way that algorithms analyse language to determine whether content is positive, negative, or neutral, and how strongly‑expressed those opinions are. This process influences how review‑clusters are weighted and how they affect overall‑perception‑assessment.
Impact on perception includes:
- Signal‑amplification: large volumes of negative‑reviews can skew SERP‑composition, making entities appear riskier than their average‑feedback might suggest.
- Bias‑locking: when negative‑sentiment becomes dominant‑in‑search, it can suppress alternative‑perspectives and create a feedback‑loop of distrust.
- Authenticity‑assessments: search engines use patterns in review‑timing, sourcing, and distribution to spot spam or manipulation, which affects how much‑weight review‑signals carry.
These dynamics show that sentiment is not just a subjective‑opinion; it is a structural‑input into how reputation is formed and deployed.
How do legal and technical frameworks shape what can and cannot be removed from search results?
Legal and technical frameworks shape what can and cannot be removed from search results by establishing the boundaries of platform‑responsibility, content‑ownership, and enforcement‑mechanisms. Laws define when content is defamatory, illegal, or harmful, while technical‑systems determine how that content is indexed, linked, and propagated across the web.
Legal‑frameworks are defined as the set of statutes and regulations that govern issues such as defamation, privacy, intellectual‑property, and data‑protection, and how they apply to search engines and publishers. These frameworks determine the conditions under which platforms must remove or delist content, and under which entities can request such actions.
Technical‑frameworks refer to the engineering‑constraints and system‑design choices that govern indexing, caching, linking, and replication across distributed‑networks. These frameworks determine how quickly‑and‑comprehensively‑removal‑requests can be implemented and how often content can reappear via backups or mirrors.
Constraints and trade‑offs include:
- Jurisdictional‑variation: different countries impose different‑legal‑standards, which complicates global‑removal‑requests and ranking‑adjustments.
- Technical‑persistence: even if content is removed from a primary‑source, it may persist in archives, caches, or third‑party‑sites that are not directly controlled.
- Transparency‑and‑appeal‑mechanisms: platforms must balance user‑safety, free‑expression, and due‑process when deciding which‑removal‑requests to act on.
These frameworks show that the visibility of harmful‑content is not simply a technical‑issue; it is shaped by a complex‑interplay of legal‑obligations and system‑constraints.
A harmful website can continue ranking after complaints because search engines treat complaints as part of an evaluation‑process, not as automatic‑removal triggers, and because ranking depends on a complex‑mix of indexing, authority, and SERP‑evaluation‑logic. Reputation within search ecosystems is constructed through the aggregation of content‑signals, the interpretation of trust and credibility, and the way that SERPs present and prioritise those signals to users.
FAQs
Why can a harmful website still rank in Google after I make a complaint?
A harmful website can still rank because complaints trigger a review process rather than automatic removal, and search engines prioritise technical, legal, and policy‑based criteria over user‑dislike. Ranking depends on indexing rules, authority signals, and whether the content clearly breaches platform‑specific guidelines or applicable law.
What happens to Google when I report a defamatory or harmful website?
When you report a defamatory or harmful website, Google evaluates the complaint against its content‑policies and legal standards, checking for evidence of defamation, illegal content, or policy violations. If the content does not meet the threshold for removal or des‑ranking, it may remain indexed and visible in search results.
How do search engines decide whether to remove or keep a harmful website in results?
Search engines decide whether to remove or keep a harmful website by assessing policy compliance, legal evidence, and technical factors such as authority, relevance, and backlink‑network behaviour. They also weigh due‑process, jurisdictional rules, and the risk of over‑removal when balancing user‑safety and information access.
Can a website with negative reviews or defamatory content stay visible in search?
A website with negative reviews or defamatory content can stay visible in search if it meets technical and quality‑criteria and does not clearly breach platform‑or‑legal‑rules. Search engines may still rank such pages, especially if they are authoritative or widely linked, but they may adjust rankings or snippets based on ongoing‑audits and user‑feedback.
What role do legal and technical routes play in removing a harmful website from Google?
Legal and technical routes play a central role by providing evidence‑based grounds for removal, such as court orders or clear policy violations, which search engines can act on within their internal‑review workflows. Without legally‑supported or system‑specific‑requests, harmful websites often remain indexed and visible until they naturally fall out of favour or are updated by the publisher.




