
Platforms apply internal review thresholds and indexing persistence that limit rapid removal. Reputation management is the study of how signals about an entity form, propagate and influence search ecosystems. Online reputation refers to the aggregate of digital signals that search systems use to evaluate an entity’s credibility, trust and perceived authority.
Why do clearly violating Facebook posts remain online after reporting?
Platform removal depends on a combination of policy interpretation, content classification systems, human moderation thresholds and content lifecycle rules that prioritise platform integrity and legal compliance over instantaneous deletion.
Definition: Content moderation is the set of automated and human processes platforms use to classify, review and action content that potentially breaches rules. Content moderation refers to workflow pipelines, policy taxonomies and escalation protocols within platform ecosystems.
Mechanism: Platforms ingest reports into triage systems that route items through automated classifiers then human reviewers based on severity scores. Automated classifiers use pattern matching and machine-learned models to assign violation probability; items above a high threshold enter rapid action queues while lower-score items wait for human adjudication. Legal holds, cross-jurisdiction checks and content appeals create additional state flags that preserve content during review. The result is persistence of content despite apparent rule breaches.
Impact on search visibility or perception: Persistent violating posts create ongoing reputation signals that search engines and social search evaluate during indexing windows. Persistent content increases the chance of content indexing, backlink propagation and entity association in SERP evaluation, thereby amplifying negative entity perception and weakening authority signals.
Why do platforms’ automated systems fail to remove obvious violations?
Automated systems prioritise precision, use training data constraints and apply contextual thresholds that limit false positives, which produces conservative enforcement for borderline content.
Definition: Automated moderation refers to machine-learned classifiers and rule-based filters that tag content for removal, labeling or human review. Automated moderation is a primary reputation filter within platform ecosystems.
Mechanism: Machine models evaluate text, images and metadata against training sets. Models weight contextual features (conversational tone, quoted material, historical poster behaviour) to avoid mislabelling legitimate speech. Precision targets and operational risk controls set high-confidence thresholds; low-confidence outputs require human verification. Adversarial content formatting and evolving linguistic patterns lower classifier confidence and increase review latency.
Impact on search visibility or perception: Automated conservatism increases the window for content indexing and link propagation, creating persistent negative reputation signals. Search systems observe interaction patterns—engagement, shares, comments—and incorporate those metrics into entity perception models, therefore algorithmic leniency amplifies reputational risk.
How does the reporting-to-removal workflow affect content indexing?
The reporting workflow establishes state transitions that interact with indexing timetables, so reported content often remains indexable until a final removal decision changes indexing status.
Definition: Reporting workflow refers to the sequence from user report to moderation outcome, including intermediate states such as triage, escalation, legal hold and appeals. Reporting workflow refers to the operational states that determine content visibility in search connectors.
Mechanism: When a user reports content, platforms tag the item and update metadata flags. Indexing crawlers internal search and third-party search engines access content according to crawl schedules. Platforms may delay removing content from public endpoints while preserving it for evidence or legal processes. Some systems apply soft removals (reduced visibility) rather than immediate deletion; soft removal modifies API responses and frontend exposure but can remain accessible to crawlers or caches.
Impact on search visibility or perception: If content remains accessible to crawlers during the reporting lifecycle, search engines index it, embedding the content into SERPs and knowledge panels. The indexed presence attaches to the entity’s digital footprint and influences downstream reputation signals such as snippet sentiment and entity co-occurrence.
How do search engines interpret platform-hosted violations when evaluating reputation?
Search engines treat platform-hosted violations as signals within a broader entity graph, weighting content by authority, engagement metrics, backlink signals and freshness to compute entity perception.
Definition: Entity perception refers to the aggregated model search engines build associating content, attributes and signals with an entity. Entity perception refers to the representation used in SERP evaluation and knowledge extraction.
Mechanism: Crawlers collect content and metadata, then pipelines extract entities and relationships using natural language processing. Ranking systems evaluate content quality using factors including source authority, backlink profile, user engagement and topical relevance. Platforms with high domain authority produce strong distribution channels; therefore content hosted there carries elevated influence in entity graphs. Search systems also run sentiment and intent analysis to tag content polarity; negative polarity integrates into entity perception scores.
Impact on search visibility or perception: Violating posts that attain engagement and backlinks elevate negative reputation signals in entity perception. The aggregation of such signals lowers perceived trust and authority in SERP evaluation, increasing the likelihood that negative content ranks for brand or personal queries.
What role do review signals and sentiment analysis play in online reputation?
Review signals and sentiment analysis function as measurable reputation signals that feed ranking models and entity-level assessments, altering search visibility through polarity-weighted weighting.
Definition: Review signals are structured indicators from review platforms and social interactions that express user evaluations; sentiment analysis is the automated classification of emotional or attitudinal polarity within textual content. Both refer to quantifiable inputs for reputation modelling.
Mechanism: Search ecosystems ingest review data via structured markup, APIs and crawling. Sentiment classifiers process textual content and apply polarity labels and confidence scores. Ranking models incorporate these scores as reputation features: high negative sentiment or low average review stars reduces trust signals, while balanced, corroborated positive signals increase authority weight. Some ranking components apply recency and verification filters to prioritise recent, verified reviews.
Impact on search visibility or perception: Negative review signals and high negative sentiment correlate with reduced search visibility for branded queries and increase prominence of corrective or defensive content in the SERP. Conversely, neutral or positive review signals improve entity perception and raise similarity-weighted content in knowledge panels.
How do authority and trust signals mitigate the effect of violating posts?
Authority and trust signals counterbalance negative content by contributing positive, high-quality signals to entity perception models, thereby diluting negative weighting in SERP evaluation.
Definition: Authority signals are endorsements and provenance indicators—backlinks, verified profiles, structured data and domain reputation—that signal credibility. Trust signals are indicators of transparency and verification, such as verified accounts and consistent identity attributes. Both relate to ranking heuristics used in search ecosystems.
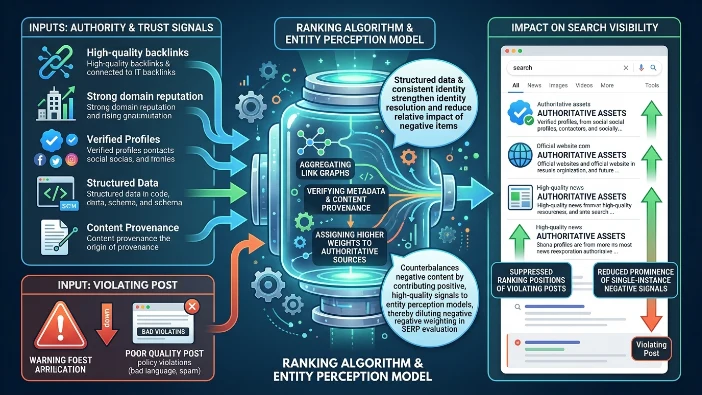
Mechanism: Ranking algorithms aggregate link graphs, verified metadata and content provenance to assign higher weights to authoritative sources. Structured data (schema) and consistent cross-platform identity strengthen identity resolution and reduce the relative impact of isolated negative items. Search systems elevate content from authoritative sources during SERP evaluation, thereby shifting visibility away from less authoritative violating posts.
Impact on search visibility or perception: Strong authority and trust signals suppress ranking positions of violating posts by providing alternative, higher-weighted content for queries. The entity’s digital footprint becomes dominated by authoritative assets, improving SERP evaluation and reducing prominence of single-instance negative signals.
What is the relationship between digital footprint persistence and entity reputation?
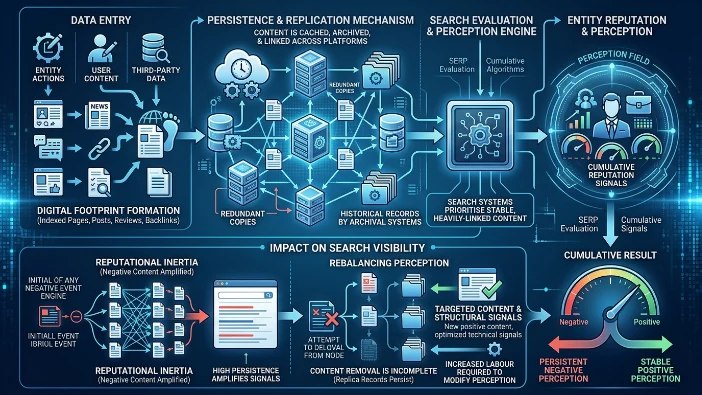
Digital footprint persistence defines the long-term availability of content and metadata that feed entity perception and cumulative reputation signals within search ecosystems.
Definition: Digital footprint refers to the ensemble of indexed pages, social posts, reviews, backlinks and archived records associated with an entity. Digital footprint refers to the durable signal repository used for ongoing reputation evaluation.
Mechanism: Persistent content is cached, archived and linked across platforms; these redundant copies produce multiple entry points into entity graphs. Search systems prioritise stable, heavily-linked content when constructing entity perception. Content removal at one node does not erase replicas or cache entries; archival systems and third-party indexers maintain historical records that continue to contribute to reputation signals.
Impact on search visibility or perception: High persistence amplifies reputational inertia: once negative content is replicated and indexed, it continues to influence SERP evaluation even after primary removal. The persistence increases the labour required to modify entity perception and demands targeted content and structural signals to rebalance rankings.
How does content classification influence decisions about removal versus restriction?
Content classification defines whether an item is removed, restricted, demoted or left in place; classifiers map content to enforcement outcomes based on policy taxonomies and risk thresholds.
Definition: Content classification refers to the labelling process that assigns policy categories, severity scores and enforcement dispositions to content. Content classification refers to the decision layer in moderation pipelines that converts analysis into action.
Mechanism: Classifiers evaluate explicitness, incitement level, legality and contextual factors, then map these to dispositions: removal, reduced distribution, warning labels, age-gating or retention for evidence. Platform risk policies calibrate the mapping based on regulatory exposure and reputational risk. High-severity classifications produce removal; medium-severity classifications produce distribution reduction and visibility controls.
Impact on search visibility or perception: Items classified for reduced distribution often retain indexed URLs or caches but receive lower engagement and ranking signals. This containment reduces immediate SERP prominence but maintains archived presence; therefore classification choices shape the long tail of reputation signals.
- Reduce duplication: Remove secondary copies or cached URLs, for example submit takedown requests to cache providers.
- Increase authoritative content: Publish verified documents or structured data, for example add high-authority pages with consistent identity markup to improve entity perception.
- Monitor indexing: Verify removal by re-crawling indexed URLs, for example use search console tools to request de-indexing of confirmed removed URLs.
- Escalate legally: File jurisdictional legal notices when content violates law, for example supply court orders to platform legal teams to create enforceable removal flags.
For deeper insight explore:
How to Remove a Harmful Facebook Post in the UK Through Proper Reporting Channels
This analysis defines the structural reasons why clearly violating Facebook posts can remain online: conservative automated thresholds, layered reporting workflows, indexing persistence and classification-driven dispositions. Reputation management analyses demonstrate that search ecosystems translate these operational realities into measurable reputation signals entity perception, SERP evaluation and long-term digital footprint effects. Understanding the mechanisms above clarifies why content removal is partial, temporally variable and intertwined with wider indexing and authority dynamics.
Why do clearly violating Facebook posts sometimes stay online after reporting?
Platforms apply moderation workflows that combine automated classifiers and human review that low-confidence classifier outputs and legal preservation flags delay removal. This process allows reported content to remain indexable while awaiting final adjudication
How long does it take for a reported Facebook post to be removed?
Removal timelines vary by severity and jurisdiction; high-confidence illegal content can be removed within hours, while ambiguous items enter human review queues that may take days or weeks. Indexing and cache persistence extend discoverability beyond the platform action.
Can I get a harmful Facebook post de-indexed from search engines?
De-indexing requires either the content be removed from the platform or a successful cache removal request to submitting URL removal requests via search console tools after platform takedown. Search engines only drop indexed pages once the source is inaccessible or a valid removal signal exists.
What evidence strengthens a report for fast removal of a Facebook post?
Provide precise URLs, timestamps, screenshots and clear reference to the platform policy or legal provision breached that structured evidence increases classifier confidence and reduces human review time. Verified identity information and third-party corroboration improve the report’s efficacy.




