
Reputation management is the discipline that defines how an entity’s public standing is constructed, measured, and managed within digital ecosystems. Online reputation refers to the sum of indexed signals, public content, and algorithmic inferences that shape an entity’s perceived credibility across search environments.
What causes harmful content to persist in search visibility after circulation ends?
Harmful content persists because content indexing creates durable records that search engines retain, catalogue, and reference across time. Indexing is the process search systems use to crawl, analyse, and store content so that it surfaces in search results. Once indexed, pages produce persistent reputation signals—URL authority, backlinks, timestamps, and content snippets—that contribute to SERP evaluation. These signals interact with algorithmic ranking factors and entity perception models that treat historical content as part of an entity’s digital footprint. Persistent presence in indexes therefore sustains search visibility even when active circulation declines.
Definition: Persistence refers to the continued availability and surfacing of content in search indexes after its primary distribution channels stop sharing it.
Mechanism: Search crawlers revisit pages and caches store snapshots; third-party archives and caches (including web caches and internal search caches) retain copies; backlinks from other domains continue to funnel authority to historical pages; meta signals (structured data, canonical tags) and sitemaps reinforce indexing. Algorithms record lexical associations and entity links that embed the content into entity graphs.
Impact on search visibility: Indexed persistence maintains SERP placement through residual ranking signals and backlinks, which sustains impression volume and influences entity perception long after circulation ceases.
How does search engine interpretation of trust and credibility cause long-term reputational harm?
Search engines evaluate trust and credibility by combining authority signals, content quality metrics, and behavioural data into a composite that influences SERP ranking. These systems define trust as a weighted construct of provenance, citation networks, and engagement signals. Harmful content that triggers negative trust deductions embeds a reputational penalty into an entity’s search profile. The penalty propagates through entity perception models, which aggregate past and present signals to inform future ranking decisions. Consequently, one instance of harmful content influences broader credibility assessments across related queries and entity-linked pages.
Definition: Trust evaluation is the algorithmic process that quantifies content reliability and source credibility within ranking models.
Mechanism: Algorithms extract provenance metadata (domain age, security headers), compute citation graphs (backlinks, references), and analyse user engagement patterns (click-through rates, dwell time). Natural language processing evaluates sentiment, factuality markers, and coherence. These inputs feed into entity graphs that attribute credibility scores to entities and content nodes.
Impact on search visibility: Lowered credibility scores reduce SERP prominence for targeted pages and related entity pages, altering the overall entity perception within search ecosystems and skewing search visibility toward negative associations.
Why do archival systems and third-party copies extend damage even after removal?
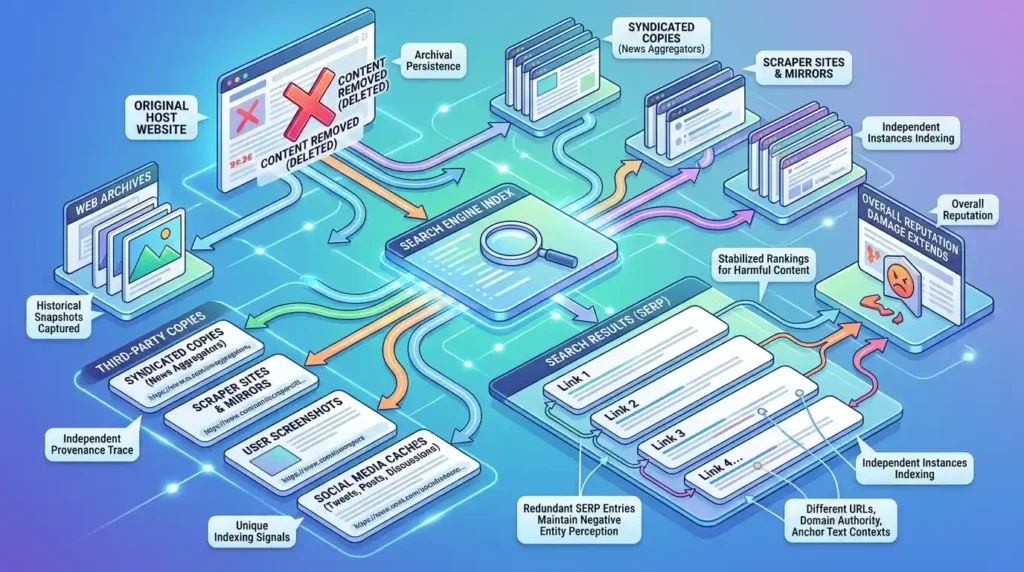
Archival systems and third-party copies extend damage because they preserve and redistribute content outside the control of the original hosting environment. Web archives, screenshots, syndicated copies, and social-media caches create independent provenance traces that search systems index separately. Each preserved copy produces unique indexing signals distinct URLs, domain authority, and anchor text contexts—that reinforce the content’s footprint. Removal from one host thus does not eliminate the multiplicity of indexed instances that contribute to overall reputation signals.
Definition: Archival persistence refers to the existence of content copies in systems outside the origin domain that remain accessible and indexable.
Mechanism: Archival crawlers capture snapshots; scrapers republish content on mirror sites; content appears in discussion threads and citation pages; caches retain HTML and metadata. Search engines index these independent instances and link them via anchor text and backlink graphs.
Impact on search visibility: Multiple indexed copies increase the number of nodes in the citation graph, stabilise rankings for harmful content, and present redundant SERP entries that maintain negative entity perception.
How does content context and co-occurrence shape entity perception in search ecosystems?
Content context and co-occurrence shape entity perception because semantic associations within indexed pages form entity networks that search algorithms use to infer relationships and relevance. Words, named entities, and topics that repeatedly co-occur with an entity generate semantic anchors that influence future query interpretation. Algorithms use these anchors to cluster content, assign topical relevance, and produce knowledge associations that extend reputational effects beyond the original piece of content.
Definition: Co-occurrence is the repeated appearance of specific terms or entities together across indexed content, which informs semantic association models.
Mechanism: Natural language processing builds vectors for words and entities; co-occurrence frequencies produce weighted links in entity graphs; topic modelling creates clusters that connect the entity to particular themes. These connections feed ranking signals and snippet generation.
Impact on search visibility: Persistent co-occurrence of negative terms with an entity elevates negative search result prominence, influences snippet selection, and alters the entity’s representation in knowledge panels and related query suggestions.
What role do backlinks and citation networks play in prolonging reputational impacts?
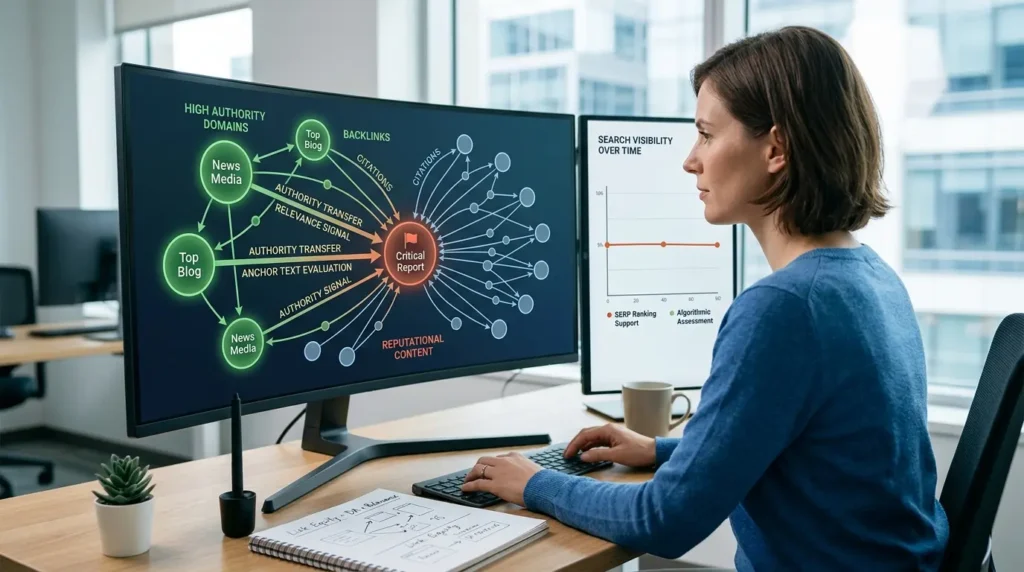
Backlinks and citation networks prolong reputational impacts because they transfer authority and relevance to indexed pages regardless of content sentiment. Each inbound link functions as a vote that influences ranking algorithms’ assessment of a page’s importance. Harmful content that accumulates backlinks—or that is cited by authoritative sources discussing it—gains persistent ranking support. Search systems evaluate the quality, topicality, and anchor text of backlinks when computing page authority, which sustains SERP visibility.
Definition: Backlink networks are the set of hyperlinks from external domains that reference a given page, shaping its perceived authority.
Mechanism: Crawlers follow links and update link graphs; algorithms calculate link equity based on referring domain authority, link placement, anchor text, and relevance. Links from high-authority sites, even if contextualised as criticism, transfer ranking weight. Citation patterns that replicate across domains amplify the signal.
Impact on search visibility: Robust backlink profiles elevate ranking positions for harmful content, increase impressions from related queries, and embed negative association within the entity’s overall search footprint.
How do review signals and sentiment analysis affect reputation in SERPs?
Review signals and sentiment analysis affect reputation because search systems incorporate aggregated user evaluations and sentiment metrics into entity-level scoring. Reviews, ratings, and aggregated sentiment provide explicit indicators of public perception that algorithms map to trust and relevance dimensions. Negative reviews that persist on review platforms or aggregator sites generate structured data and review snippets that appear in SERPs, reinforcing negative entity perception.
Definition: Review signals are structured or semi-structured data points (ratings, review text, reviewer identity) that inform algorithmic reputation assessments. Sentiment analysis is the automated classification of review tone and language to quantify positivity or negativity.
Mechanism: Algorithms parse structured review markup (schema.org), calculate average ratings, and apply sentiment algorithms to unstructured review text. Aggregated sentiment integrates with other entity signals to adjust perceived credibility. Review platform authority and reviewer reputation weight the final contribution to reputation scores.
Impact on search visibility: Negative review aggregates and negative sentiment snippets appear in search results and lower organic visibility for preferred pages, shifting searcher perception toward negative evaluations.
How does jurisdiction and platform type influence the persistence and removal effectiveness of harmful content?
Jurisdiction and platform type influence removal effectiveness because legal frameworks, platform policies, and technical architectures determine content lifecycle control. Different jurisdictions establish distinct removal orders, defamation thresholds, and data-retention rules that affect whether content becomes legally erasable. Platform type—centralised platforms, decentralised networks, archives, or caches—defines technical ability to delete content and the likelihood of replication. These structural differences create heterogeneous outcomes for reputation remediation.
Definition: Jurisdictional variation refers to the differences in law and regulation across national boundaries that affect content takedown and retention. Platform type classification identifies the architectural and governance model under which content is hosted.
Mechanism: Courts issue removal or delisting orders within legal jurisdictions; platforms enforce content policies and retention schedules; decentralised systems lack centralised removal controls, enabling persistence through replication. Cross-border hosting and caching complicate enforcement by creating multiple independent indexable instances.
Impact on search visibility: Legal orders and platform-level removals reduce localised indexing and may trigger delisting in specific search markets. However, cross-jurisdictional copies and cached instances sustain global indexing, limiting the removal’s effect on aggregate search visibility.
Dive Deeper With Our Expert Guides:
How to Remove Content From the Internet Depending on Where It Is Hosted
How a Content Removal Agency Approaches Cases That Individuals Cannot Resolve Alone
What structural interventions reduce long-term search damage from harmful content?
Structural interventions that reduce long-term damage target the indexing, authority, and co-occurrence mechanisms that sustain negative content. Interventions that change indexing status, disrupt backlink flows, or recontextualise content in authoritative sources modify reputation signals at the algorithmic level. System-level mitigation relies on altering signal strength rather than solely eliminating individual items.
Definition: Structural interventions are actions that modify systemic inputs to ranking models—indexing directives, link profiles, and semantic associations—rather than isolated content deletion.
Mechanism: Apply indexing control through consistent use of noindex directives, canonical tags, and removal of sitemaps; reduce backlink impact by disavowing or neutralising low-quality inbound links, and address co-occurrence by producing countervailing semantic context in authoritative content. Algorithms re-evaluate as signal weight shifts, rebalancing entity perception.
Impact on search visibility: Systemic signal modification reduces the prominence of harmful items across SERPs, lowers the frequency of negative snippet generation, and adjusts the entity’s overall search footprint toward alternative associations.
- Remove indexing references: Submit removal requests to search operators, provide HTTP status changes or noindex metadata, which detaches the page from index state.
- Neutralise backlinks: Disavow low-quality referring domains via search console tools or request link removals, which decreases link equity transferred to harmful pages.
- Recontextualise content: Publish authoritative, high-quality content that addresses the same topics, which creates competing semantic anchors and dilutes negative co-occurrence signals.
- Suppress replication: Identify archives and mirror sites, then submit targeted removal or rights-based requests to reduce independent indexed instances.
- Correct review signals: Solicit verified reviews and ensure review schema accuracy, which adjusts aggregated sentiment metrics and improves reputation signals.
Get more insight explore:
How Removing Harmful Online Content Differs by Platform Type and Jurisdiction
Harmful content causes lasting damage because search ecosystems convert transient publications into durable reputation signals through indexing, backlinking, semantic association, and trust evaluation. Algorithms integrate provenance, citation, and sentiment data into entity perception models that propagate negative associations across queries and time. Effective mitigation requires structural interventions that alter indexing status, citation networks, and semantic context rather than relying solely on single-instance removals. Understanding these system-level mechanisms clarifies why harmful content persists and how search-driven reputational effects form and endure.
Answers to Key Questions
How do I report harmful Facebook content to Clear Your Name?
Collect the exact post URL, screenshots, and a brief explanation of the policy or legal breach (defamation, privacy, copyright). Clear Your Name uses that documentation to prepare platform reports and to identify subsequent steps for search visibility remediation.
Will removing a Facebook post delete it from Google search results?
Removing the original Facebook post stops further platform circulation but search engines may retain cached or archived copies. Clear Your Name recommends submitting search operator removal requests and checking web caches to reduce indexed remnants.
What proof is required for a successful Facebook content removal request?
Provide direct URLs, dated screenshots, context showing the violation, and identity verification or court orders when relevant. Clear Your Name notes that specific legal documentation accelerates platform and search operator decision-making.
Does my country’s law affect Facebook content removal outcomes?
Yes; jurisdiction defines legal thresholds, enforceability of takedown orders, and platform obligations, which shape removal scope and cross-border indexing. Clear Your Name states that legal and platform policy differences influence the effectiveness of content removal and subsequent search perception.




