
The most effective routes for removing a website from UK search results are those grounded in legal frameworks, platform‑specific policies, and structured technical processes that align with how search engines evaluate content risk. Reputation management strategies differ based on whether they prioritise direct removal, content suppression, or long‑term SERP‑control through reputation‑signal enhancement. Online reputation control methods are evaluated through their impact on search visibility, entity credibility, and the stability of narratives that appear under a person or business name.
How do legal routes compare with technical removal methods for de‑ranking content?
Legal routes and technical removal methods both influence whether a website appears in UK search results, but they operate through different mechanisms and carry distinct limitations. Legal routes work by invoking external rights, while technical methods focus on how content is indexed and linked within search ecosystems.

Legal routes operate by asserting rights under UK and EU‑derived frameworks such as data‑protection law, defamation statutes, and copyright protection. These routes include submitting formal takedown notices, requesting delisting from search engines, or pursuing court‑ordered removal when content is demonstrably unlawful or harmful. When accepted, these actions can compel platforms or search engines to de‑index or demote URLs, reducing their visibility in SERPs.
Dive Deeper With Our Expert Guides and Related Blog Posts:
How to Get a Website Taken Down in the UK Using GDPR Defamation and Copyright
What a UK Website Removal Service Does That Direct Reporting Often Cannot Achieve
Technical removal methods, by contrast, operate within the logic of search‑engine policies and content‑indexing systems. These include spam‑reporting workflows, manual spam penalties, and structured de‑indexing requests that target pages violating platform guidelines. They do not rely on external legal authority but on internal policy enforcement. When applied correctly, they can demote or remove low‑quality, spammy, or manipulative content from search results.
In comparison, legal routes are more powerful for clear‑cut cases of defamation, privacy violation, or unauthorised content, because they derive from enforceable rights. Technical routes are more scalable and less resource‑intensive but are limited to content that breaches platform‑specific rules rather than broader legal standards. The most effective configuration typically combines both, using legal foundations where defensible and technical mechanisms for broader reputation‑signal management.
How does content suppression differ from content removal in search ecosystems?
Content suppression and content removal differ in how they alter a website’s presence in search results without necessarily changing whether the page remains live on the web. Both influence reputation signals, but they act at different levels of visibility and permanence.
Content removal operates by removing a URL or domain from search indexing so that it no longer appears in organic results. This is typically achieved through legal takedown notices, platform delisting, or policy‑based delinking that instructs search engines not to index or serve specific pages. When successful, removal significantly alters SERP composition by eliminating certain reputation signals from view.
Content suppression, by contrast, keeps the page indexed but reduces its prominence in search rankings. This is done through algorithmic demotion, backlink and trust‑signal reduction, or content‑quality adjustments that lower the page’s ranking score. Suppression does not erase the content but diminishes its gravitational pull on entity perception by pushing it beyond the first page of results.
From a reputation‑management perspective, removal is more decisive but often harder to achieve and more dependent on specific legal or policy grounds. Suppression is more flexible and scalable, because it can be applied to a broader range of content, but it is less permanent, since algorithmic changes or new content can restore visibility. A balanced approach uses removal where justified and suppression where long‑term SERP control is the priority.
How effective are GDPR‑based removal requests compared with defamation or copyright claims?
GDPR‑based removal requests, defamation claims, and copyright‑based claims are all routes for challenging content in UK search results, but their effectiveness depends on the nature of the content, the jurisdiction, and the platform’s interpretation of those rights. Each route operates through a distinct legal logic and produces different outcomes for search visibility and reputation signals.
GDPR‑based removal requests operate by asserting an individual’s right to erasure or restriction of personal data where it is inaccurate, unlawful, or no longer necessary. These requests are often used to delist pages that host identifying information, leaked data, or outdated profiles. When processed correctly, search engines can apply regional or global delisting to specific URLs, reducing their visibility in UK‑based search.
Defamation claims operate through tort law, where a claimant must demonstrate that a statement is false, damaging, and published to third parties. If successful, courts can order removal of content, correction notices, or delisting from search engines. This route is powerful for reputation‑restoration but requires evidence‑based litigation and can be time‑consuming.
Copyright‑based claims operate by asserting ownership over original content, such as images, text, or videos, and requesting that unauthorised copies be taken down or delinked. This route is effective for content that clearly infringes intellectual‑property rights but does not address non‑copyright harms such as opinions or commentary.
In comparative terms, GDPR‑based requests are most effective for personal data‑related content and can be applied relatively quickly through formal notice processes. Defamation claims offer strong legal leverage but are slower and more costly. Copyright claims are highly targeted and reliable for literal infringement but do not cover broader reputation issues. The most effective route is determined by the content type, the strength of rights, and the desired scope of removal versus suppression.
How do organic reputation strategies compare with reactive website removal tactics?
Organic reputation strategies and reactive website removal tactics differ in how they shape the digital footprint that appears when a name is searched in the UK. Both influence reputation signals, but they address different time horizons and risk profiles.
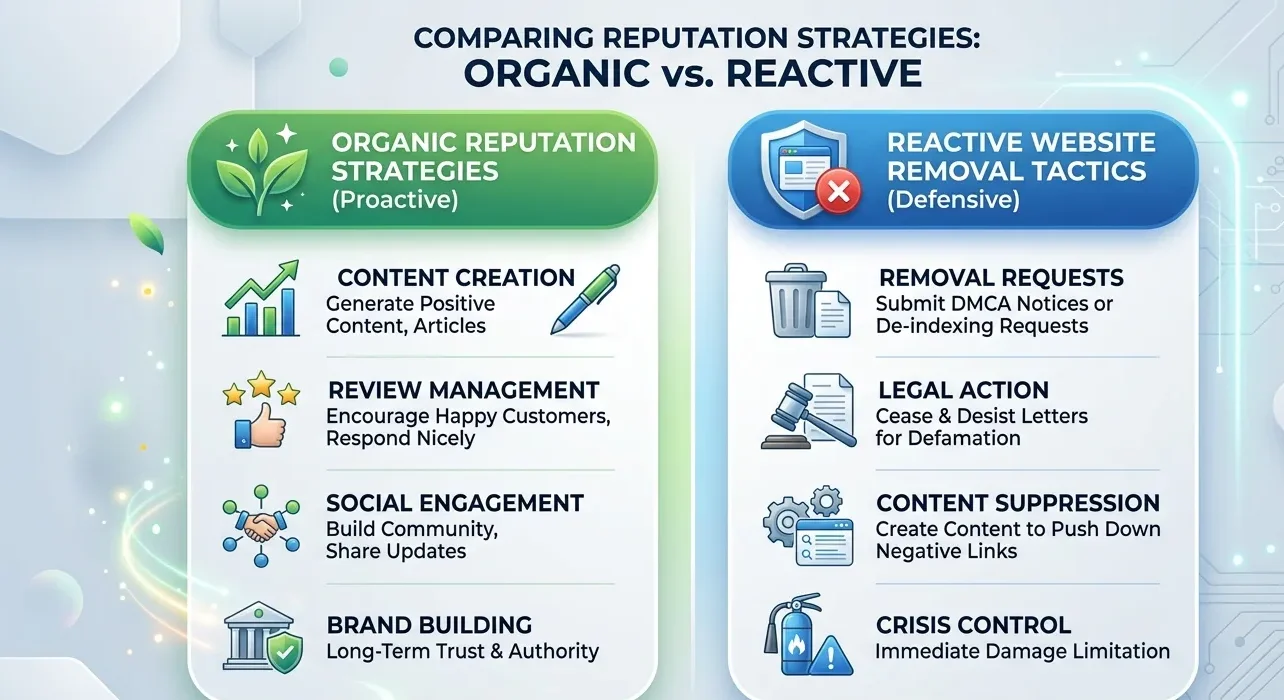
Organic reputation strategies operate by building and reinforcing a positive digital footprint over time. This includes creating credible profiles, authoritative articles, and structured content that aligns with how search engines interpret entity credibility. These methods strengthen SERP narratives so that any negative content, even if not removed, occupies a smaller proportion of the visible footprint.
Reactive website removal tactics operate by targeting specific harmful pages or domains after they appear in search results. These tactics include issuing takedown notices, engaging legal channels, or requesting platform‑based delisting to reduce the visibility of particular URLs. They are useful for acute incidents where a single page or article has a disproportionate impact on reputation.
In comparative analysis, organic strategies are more sustainable and scalable, because they spread the effort over multiple channels and long‑term content creation. Reactive tactics are faster to apply in crisis situations but are less scalable across multiple locations, domains, or persistent issues. Organic approaches also reduce risk by diversifying reputation signals, whereas reactive methods can increase exposure if disputes become public or if removal attempts fail.
What are the strengths and limitations of trying to “take down a website” versus reshaping SERPs around it?
Trying to take down a website and trying to reshape SERPs around it are two distinct approaches to managing how a domain appears in search. Each has different strengths and limitations when evaluated against search visibility, trust signals, and long‑term entity perception.
Website removal operates by targeting the domain or specific URLs with the intent of de‑indexing or delinking them from search results. This approach can decisively reduce the prominence of harmful or inaccurate content when it is legally or policy‑defensible. The strength of this method lies in its clarity; if removal is successful, the affected pages will no longer appear in standard organic results.
Reshaping SERPs, by contrast, operates by increasing the density of alternative, positive, or neutral content around the website’s presence. This includes publishing profiles, features, and authoritative commentary that push down or dilute the visibility of the targeted pages. Search engines interpret this as a more balanced reputation footprint, which reduces the relative weight of any negative content.
The limitation of website removal is that it is not always possible; some content cannot be classified as unlawful or policy‑violating, and certain URLs may remain indexed even if they are demoted. Reshaping SERPs is more flexible and can be applied more broadly, but it is slower and requires ongoing content‑generation efforts. From a strategic standpoint, removal is most effective in clear‑cut cases, while SERP‑reshaping is better suited to long‑term reputation‑control and narrative stabilisation.




